
はじめに
本記事では、データパイプラインの概念、構成要素、そしてデータ分析・機械学習のプロセスについて詳しく解説します。ビジネス領域におけるデータ利活用は非常に重要な役割を持っていますが、生のデータだけでは意味をなしません。蓄積されたデータから価値を引き出すためには、効率的なデータパイプラインと適切な分析プロセスが不可欠です。さらに、最新の技術トレンドや実践的なツール、そしてデータガバナンスの重要性についても触れていきます。
データパイプラインとは
データパイプラインとは、データの収集、処理、分析、管理を行うためのプロセスやツールの総称です。その主な目的は、事業やサービスにおけるデータの効果的な利活用を実現することにあります。
データレイク (Data Lake)
データレイクは、データの形式や構造に関係なく、すべてのデータを蓄積します。必要な時にオリジナルのデータを参照することができます。
- 役割:未加工の生データを大量に保存
- 主なユーザー:データ基盤管理者
- 使用されるツール例:Apache Hadoop, Amazon S3, Azure Data Lake Storage
データウェアハウス (Data Warehouse)
データウェアハウスは、データレイクから取り込んだデータを処理・保存します。欠損値・異常値の処理を施し、データ分析やビジネスインテリジェンスに特化した形で保存します。
- 役割:構造化されたデータの集中管理と分析のための最適化
- 主なユーザー:データサイエンティスト、ビジネスアナリスト
- 使用されるツール例:Amazon Redshift, Google BigQuery, Snowflake
データマート (Data Mart)
データマートは、データウェアハウスから特定部門や用途に応じてデータを取り込み、整形します。フィルタや集計処理などで見やすい形にまとめ、迅速なダッシュボード化やレポート作成を可能にします。
- 役割:特定の部門や用途に最適化されたデータの提供
- 主なユーザー:各部門のビジネスユーザー、意思決定者
- 使用されるツール例:Tableau, Power BI, Looker
データ処理の最新トレンド
データ処理技術は急速に進化し続けており、ビジネスニーズの変化に合わせて新しいアプローチが生まれています。その中でも特に重要な、ストリーミングデータの処理と統合プラットフォームについて紹介します。
バッチ処理とリアルタイム処理
従来のデータパイプラインは主にバッチ処理を中心としていましたが、近年ではリアルタイムデータ処理の重要性が増しています。
- バッチ処理:大量のデータを定期的に処理
- ツール例:Apache Hadoop, Apache Spark
- リアルタイム処理:データをストリームとして連続的に処理
- ツール例:Apache Kafka, Apache Flink, Apache Spark Streaming
統合プラットフォーム
データエンジニアリングからデータサイエンス、MLOpsまでを一貫して管理できる統合プラットフォームも登場しています。
主なデータ統合プラットフォーム
- Databricks:
- Delta Lake(信頼性の高いデータレイク)
- 協調的なノートブック環境
- MLflow(機械学習ライフサイクル管理)
- Google Cloud Platform:
- BigQuery(サーバーレスデータウェアハウス)
- Dataflow(ストリーム/バッチ処理)
- Vertex AI(MLOps)
データ分析・機械学習のプロセス
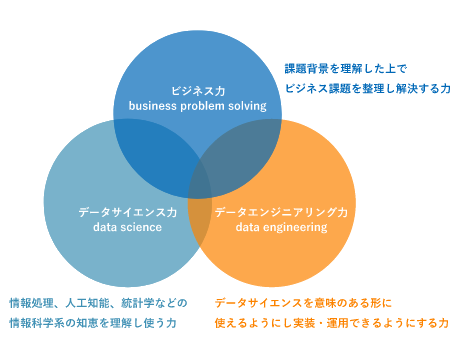
効果的なデータ活用には、以下の3つの力が重要です。
https://www.datascientist.or.jp/dscertification/what/
- ビジネス力
- ビジネス課題を整理し、解決策を設計する
- データ分析の目的を明確化し、結果をビジネスアクションに結びつける
- データサイエンス力
- 統計学や機械学習・人工知能の知識を活用し、データから洞察を導き出す
- データエンジニアリング力
- データの収集、クレンジング、などデータを意味のある形に変え、実装・運用する
- 効率的なデータパイプラインを構築・維持する
データエンジニアリングの前処理
データ分析や機械学習の精度を高めるためには、適切な前処理が不可欠です。主な前処理の手順は以下の通りです。
- データクレンジング
- 不正確または不完全なデータを修正・削除
- 例:欠損値の処理、外れ値の検出と処理、重複データの削除
- ツール例:OpenRefine, Trifacta Wrangler
- データ統合
- 複数のソースからのデータを結合し、一貫性のあるデータセットを作成
- 例:顧客データと取引データの統合、異なるシステムからのデータの統合
- ツール例:Talend, Apache NiFi
- データ変換
- データ形式の変更、計算、エンコーディングを行い、分析に適した形式に変換
- 例:カテゴリカル変数のエンコーディング、スケーリング、特徴量エンジニアリング
- ツール例:pandas (Python), dplyr (R)
データ品質管理
データ品質は、分析結果の信頼性に直結します。以下のような観点からデータ品質を定義し、継続的に管理することが重要です。
- 正確性:データが現実を正確に反映しているか
- 完全性:必要なデータが欠落していないか
- 一貫性:異なるシステム間でデータに矛盾がないか
- 適時性:データが最新の状態に保たれているか
データ品質管理のためのツールとして、Talend Data Quality, Informatica Data Quality などがあります。
データガバナンスとセキュリティ
データの価値が高まる一方で、そのガバナンスとセキュリティの重要性も増しています。
データガバナンス
- データの所有権と責任の明確化
- データカタログの整備(Alation, Collibra など)
- データリネージの追跡(どのデータがどこから来たのか)
データセキュリティ
- アクセス制御と認証(役割ベースのアクセス制御)
- データの暗号化(保存時と転送時)
- 個人情報保護法などの法令遵守
業種別のデータパイプライン活用例
小売業・製造業・ヘルスケア業界を例にデータパイプラインの活用例を示します。
小売業
- データレイク:
- 店舗のPOSシステムから得られる販売データ
- オンラインストアのクリックストリームデータ
- 在庫管理システムからの在庫データ
- 顧客のロイヤリティプログラム情報
- データウェアハウス:
- 日次・週次・月次の売上集計テーブル
- 商品カテゴリー別の在庫回転率テーブル
- 顧客セグメント別の購買行動分析テーブル
- データマート:
- マーケティング部門:顧客セグメント別のキャンペーン効果分析
- 商品企画部門:季節別・地域別の人気商品ランキング
- 店舗運営部門:店舗別のパフォーマンス指標ダッシュボード
活用例
- 需要予測に基づく自動発注システム
- パーソナライズされたレコメンデーション
- 異常検知を用いた不正取引の防止
製造業
- データレイク:
- 生産ラインのセンサーデータ
- 品質検査データ
- サプライチェーン情報
- データウェアハウス:
- 生産効率分析テーブル
- 品質管理指標テーブル
- 在庫最適化分析テーブル
- データマート:
- 生産管理部門:生産ライン別のパフォーマンス分析
- 品質管理部門:不良品発生率と要因分析
- 調達部門:サプライヤーパフォーマンス評価
活用例:
- 予知保全(Predictive Maintenance)
- 生産ラインの最適化
- サプライチェーンの可視化と最適化
ヘルスケア
- データレイク:
- 電子カルテデータ
- 医療機器からのセンサーデータ
- 臨床試験データ
- データウェアハウス:
- 患者の治療経過分析テーブル
- 疾病傾向分析テーブル
- 医療リソース利用状況テーブル
- データマート:
- 臨床部門:治療効果分析
- 研究部門:臨床試験データ分析
- 運営部門:病院運営効率分析
活用例:
- 個別化医療のための患者分類
- 疾病の早期発見・予防
- 医療リソースの最適配分
データサイエンティストとデータエンジニアの協働
データパイプラインの効果的な構築と運用には、データサイエンティストとデータエンジニアの緊密な協働が不可欠です。
- 共通言語の確立:
- 技術用語や業務用語の定義を明確にし、チーム内で共有
- 定期的なコミュニケーション:
- スプリントレビューやデータ品質レビューの実施
- ツールの共有:
- バージョン管理システム(Git)の活用
- 協調的な開発環境(Jupyter Notebook, RStudio Server)の利用
- 役割の相互理解:
- データエンジニア:分析に必要なデータの特性を理解
- データサイエンティスト:データパイプラインの制約を理解
- 継続的な学習と知識共有:
- 社内勉強会やハッカソンの開催
- 外部カンファレンスへの参加
その他のデータ・AI領域のトピック
データエンジニアリングとデータサイエンスの分野のさらなるトピックについて紹介します。
- MLOps(機械学習オペレーション):
- 機械学習モデルの開発から運用までを一貫して管理
- ツール例:MLflow, Kubeflow, Amazon SageMaker
- データメッシュアーキテクチャ:
- 分散型のデータアーキテクチャ
- データの所有権と責任を分散させ、柔軟性と拡張性を向上
- エッジコンピューティング:
- データソースの近くでデータを処理
- レイテンシの削減とプライバシーの向上
- AutoML(自動機械学習):
- 機械学習モデルの自動開発・最適化
- ツール例:Google Cloud AutoML, H2O.ai
- 説明可能なAI(XAI):
- AI/機械学習モデルの判断根拠を人間が理解可能な形で説明
- 特に金融や医療など、説明責任が重要な分野で注目
まとめ
データの収集から分析までの一連の流れを支えるデータパイプラインについてまとめました。効率的なデータパイプラインを構築し、適切な分析プロセスを実施することで、組織はデータから最大限の価値を引き出すことができます。
ビジネス力、データサイエンス力、データエンジニアリング力を組み合わせ、最新のツールとトレンドを活用することで、データ駆動型の意思決定が可能となり、競争力の強化につながります。同時に、データガバナンスとセキュリティにも十分な注意を払い、責任あるデータ活用を心がけることが重要です。
さらに学びたい方へ
Udemyのこちらの動画が勉強になります。英語の動画もありますが字幕もあって分かりやすいです。
(Udemy動画は結構高いものもありますが、セールで80%OFFになったりもするので、セールのタイミングで一気に購入してしまうのがおすすめです)


コメント